202110 - IPAプロジェクトマネージャ試験を受けてきた(追伸: 不合格だった)
先日行われた2021年度IPAプロジェクトマネージャ試験を受けてきた。
ちゃんとした振り返りは後日行うとして、一旦 今の気持ちを吐露しよう。
自分はどんな人
- webエンジニア
- IPAまわりだと データベース、セキュリティ、ネットワークは取得済
- 今回初めてマネージメント系の試験を受ける
- 古本屋で購入した ALL IN ONE パーフェクトマスター プロジェクトマネージャ 2020年度 (情報処理技術者試験) を用いて学習
試験に至るまでの感想
結論から。今まで受けてきたIPA試験に比べると、簡単な印象。
参考書にはあれこれ書いてあるが、すべてを詳細に理解せずとも問題は解ける。
他のIPA試験では、概念そのものを理解する必要があったが、
マネージメントは、最終的には人間関係に帰結するため、今までの人生経験で補えるものが多い印象。
例えば、学生時代 部活で次回の試合に向けて
- 目標・戦略をチームメンバで議論する。
- 目標に向けて計画を立てる。
- 実践する。修正する。
こんな経験があれば、理解しやすい印象。
新しい用語もあるが、経験に紐づくものが多いので、覚えやすい。
思想的な部分も、経験に基づく基盤があるため受け入れやすい。
今までの試験に比べてかける時間も最も少なく済んだ。
子育ての合間時間でこなしていた身としては助かった。
試験を受けてみて
簡単と言っておきながら、当落線上の印象。。。ずっこけ。
理由は午後1。
今までは、ウォーターフォール が前提の問題ばかりだったが、
問1、問2ともにアジャイルが前提となっていた。
不確実性を受け入れるアジャイルが前提となったことに伴ってか、
過去問では問題文の中に答えが記載されていることが多かったが
自分で要約する問題が増えた印象。
過去問に過学習しすぎてしまっていたためか、今までの形式の押し込めようとするバイアスが働き
柔軟に回答ができなかった。反省。
まだ、公式解答は出ていないが、TACやitecの解答速報を見てみても解答にばらつきがあり、
自己採点しても どちらにしろギリギリかなぁという印象。
参考書をケチって古いものにしたことも仇になったか。反省。
今年PMBOKの7版が発行され、大きくアジャイルにシフトチェンジしたことが話題になったが、
思いの外早く、対応してきた印象。
今後、PM試験はアジャイルを意識した問題の割合は増えること。すなわち時代に即した試験になることは自明。
今回未受験の方は、来年以降受験するといい勉強になるかも。
追記: 結果が届いた
落選。
試験後の所感どおり、午後1が数点足らなかった模様。
残念。
だが、付け焼き刃ではなく、よし本質的に・深く マネージメントを理解するためのきっかけとなるように。
また来年チャレンジするぞ。
ということで次回に向けた反省
- 参考書はケチらず最新のもの買おう...
- 半年前くらいから学習スタートして 試験範囲のみならずマネージメント全般について学んでいこう
202109~202203 ロードマップ
202104~202109 の成果
こどもうまれた
一世一代の大成果!
資格
その他成果物
特になし。 来期以降意識する。
振り返りと今後の展望
今期は、新しい知識の取得を中心に行った。
取得した知識は、それぞれ基礎レベルなので、今後応用レベルに発展させていきたい。
また、来期はwebエンジニアとしてマネージメント・技術 双方の知識ベース向上にも取り組みたい。
前者は、まずはIPA PM試験を受けてみる。そこで基礎を固めて、さらに深掘りしていけたら。
後者は、テーマを見つけるところから。
風呂敷広げすぎてもやりきれないので、フロントエンド回りに行くか、クラウドネイティブまわり行くか。
ちょっと考える。
その他トピック
202109 新しいチームに異動
育児休暇明けに伴い、チーム異動。
新しいチームでは DDDを積極的に採用している模様。
いい機会なので今期かけて設計思想まわりも勉強しよう。
202309 ラグビーW杯フランス大会
2年後、家族でフランスに行く。
直近、私生活では 最大の楽しみ。かつ、最大の目標。
適当なボディランゲージでなんとかなった一人旅と異なり
家族の安全を守るためには、ちゃんとした語学力必要。
いい機会。これを動機に、まずは今期、英語学習。
+余裕があったらフランス語もかじってみたい。
趣味
音楽作れるようになりたい
しなぷしゅの音楽が流れるとパッと泣き止む我が子。
自分も我が子の何か心に残る音楽を作ってみたい。
そう思った。
仕事の余裕を見つつ、チャレンジできることがあればしてみよう。
来期以降のロードマップ(随時更新)
202107 - 統計検定 2級 (CBT) に合格しました (勉強法・所感など)
統計検定2級(CBT)に合格しました。
合格までの経緯をまとめます。
これから受験する方の参考になれば幸いです。
合格証

うむぅ。ギリギリ。まぁよしとしよう。
TODO: 正式な合格証が届いたら載せる
最初に私ってどんな人?
恥ずかしながら...試験前はこの程度のレベルでした。
勉強期間
- 1~2ヶ月ほど
目的・動機
統計に関する基礎知識を身に付けたかった
もっとも原始的な動機としては、
データ解析時に、客観的な視座から説得力のある提案をできるようになりたかったからです。
ログの解析やA/Bテストの結果判断など、業務の中でデータを解析することは多々あります。
その際、ユーザにどのような傾向があるのか?AとBどちらが良いのか?など
なんとなくのデータの傾向から判断していました。
主観ではなく客観で。定量的な指標とともに。解析結果を提案したい。
そのような思いから、必要となるデータ解析リテラシー取得のために、今回受験を決意しました。
合格までの道のり
教材
- 主教材
問題集
補足
やったこと
- 統計webを一周読む
- 過去問を解く
- 解けなかった箇所を統計webで復習
- 気分転換でyoutubeで知識補充
振り返ってみて
統計web一周目はサクッと読めばよかった
少し時間をかけすぎた気がします。
加えて、初段から、すべてを理解しようと思って負荷をかけすぎた気がします。
初学者が 一つずつ理解していくには、統計webのボリュームは大きいです。
サクッと要点だけ確認して進み、全体像の把握 => 問題演習の流れ の繰り返しで定着の方が
効率良かったと反省。
まぁ、そもそも知識がないとその要点だけ抽出することが難しいわけですが。
どちらにしろ。最初は力を抜いて。を次回以降も意識してみようと思います。
next step
今回得た知識はあくまで基礎の基礎。
今後、統計検定準1級を目標に
さらなるチャレンジをして行こうかと思います。
加えて実務レベルでもう少し使いこなせるようになりたいので
その点も追加で学習していきたいと思っています。
202103 - ビジネス会計検定試験 3級 に合格しました (勉強法・所感など)
ビジネス会計検定試験3級に合格しました。
合格までの経緯をまとめます。
これから受験する方の参考になれば幸いです。
合格証
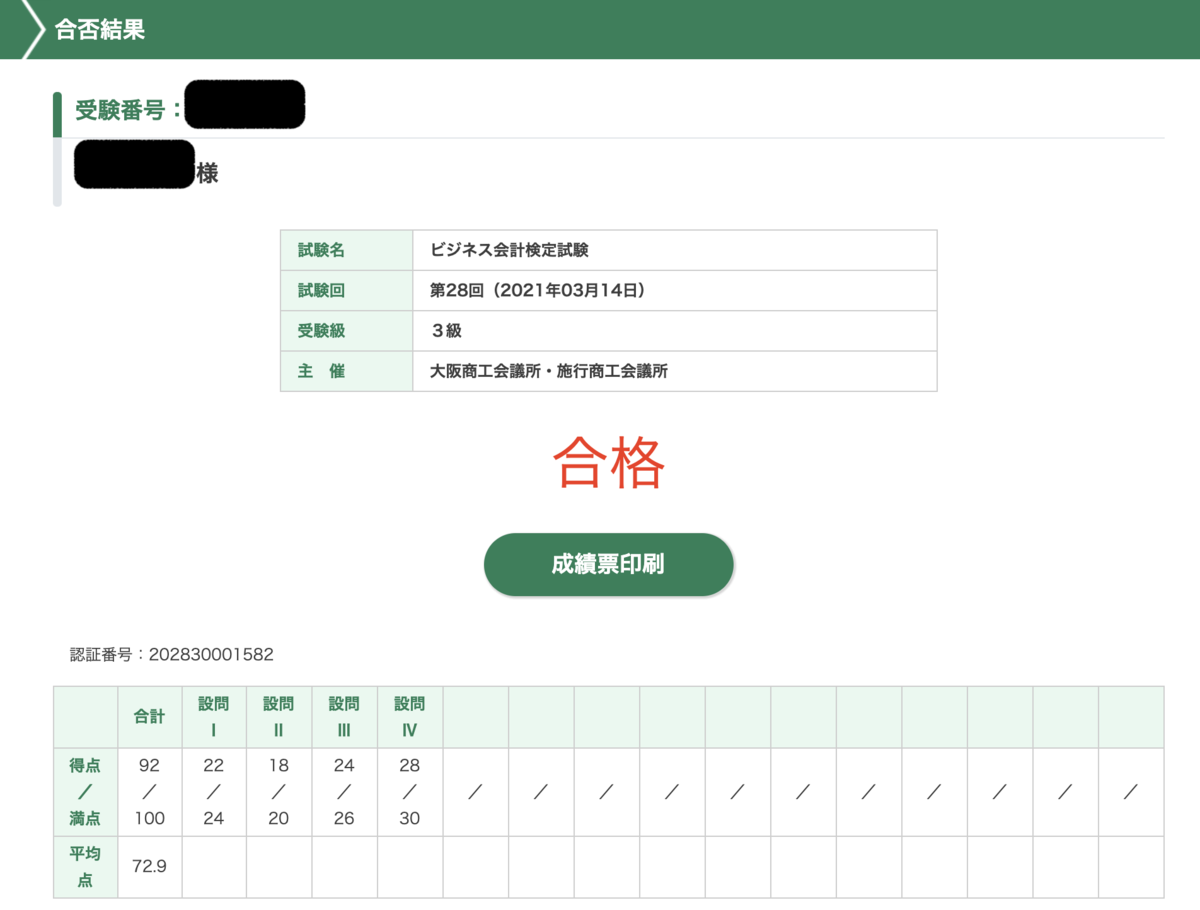
最初に私ってどんな人?
恥ずかしながら...試験前はこの程度のレベルでした。
目的・動機
会計に関する基礎知識を身に付けたかった
もっとも原始的な動機としては、
自分の会社へのコミットがどれくらい業務成績に反映しているのか
理解できるようにしたかったからです。
目の前の案件を全力でこなしてはいるものの、その結果どのような利益につながっているのか。
局所的には把握してはいるが、もっと大局的な視座から把握したい。
そして、さらなる業務提案をしていきたい。
そのような思いから、必要となる財務諸表のリテラシー取得のために、今回受験を決意しました。
合格までの道のり
やったこと
本
公式のテキスト・問題集だけ で十分でした。
youtube
初段。知識不足から、いきなり公式テキスト に入るのが少し辛かったのでyoutubeを活用しました。
ほらっち先生のチャンネルが わかりやすかったです。
合格するには、不十分ですがはじめの一歩としては最適。
すごくスムーズに知識導入ができました。
ポイント
一つ一つ完全に理解するのではなく・繰り返し理解する
初段、一つ一つの項目を理解しながら学習を進めていましたが
基礎知識がない状態で、一つ一つに こだわっていると、
なかなか前に進まない状況に陥りました。
途中から方針転換し
ざっくりでいいから、理解して先に進む。
繰り返し学習しながら、問題集で知識定着。
少しずつ肉付けしていく。
このように学習を進めてから、スムーズに前進することができました。
今分からなくても、必ず後からわかるようになるから大丈夫。の精神。
試験勉強してみて・受かってみて
結論から。
今回、ビジネス会計検定試験を受験してみて本当に良かったです。
理由は、会計まわりのドメイン用語を聞いたときに
パッと知識の結びつきができるようになったからです。
会計に関する基礎知識がインプットされたことで、
自社の財政状況も客観的に理解できるようになりました。
加えて、経済ニュースも理解しやすくなりました。
next step
今回、得た知識はあくまで基礎の基礎。
これを基にさらなるチャレンジをして行こうかと思います。
- 資格・学習
- ビジネス会計検定試験2級
- 簿記2級
2021#01 G検定に合格しました (勉強法・所感など)
ディープラーニングを中心としたAIに関する資格であるG検定に合格しました。
合格までの経緯をまとめます。
これからG検定を受ける方の参考になれば幸いです。
合格証

目的・動機
1: AIに関する基礎知識を身に付けたかった
近年、AIという言葉をよく耳にします。
AIとは。私自身、わかっているようでわかっていない。 そんな状況でした。
AIとは?AIを使って何ができるのか?
それをしっかり理解するためのステップとしてG検定受験を決意しました。
G検定でAIの基礎知識を身に付けた上で、業務や個人開発に応用できればと思っています。
2: 会社から出る奨励金が欲しかった
お金大事。
勉強開始前の状態
このような状態でした。
合格までの道のり
やったこと
1: 本
以下の本を読み進めました。
基本的には、こちらの本だけで十分でした。
2: 模試
試験直前に以下の模試を受けました
どちらの模試も実際の問題に近く、とても役に立ちました。
3: youtube
勉強内容の補足にyoutubeを活用しました。
ポイント
個人的に重要だと感じたポイントを残します。
1: 基本的には 公式テキスト+問題集 で十分
ブログを漁ると、公式テキストだけだと不十分だとちらほら出てきます。
たしかに満点を取るには不十分かもしれませんが、
合格するには公式テキストの内容だけで十分でした。
特に、私のようにAIに関する前提知識がない場合
あれこれ公式テキスト以上に風呂敷を広げるのではなく、
まずは、公式テキストの内容をガッチリ固めることが重要
だと個人的には感じました。
2: 余裕があればAI白書で社会・法律問題
たしかに公式テキストだけだと、
最新の社会動向、法律問題に対応できません。
基礎知識をしっかり固めた上で、
余裕に応じて AI白書 を用いて最新情報をピックアップしましょう。
私は、直前までそれほど余裕がなかった + それほどお金もかけたくなかった ので
試験数日前に 過去のAI白書(無料で公開されています) を さーっとだけ 眺めました。
ちなみにAI白書は、図書館にも貯蔵されているようなので、
興味がある方は、まずは図書館で眺めてみるといいかもしれません。
3: 重要な物から理解する
公式テキストを1章から順々にやるよりも
ディープラーニング(DL)手法、DL応用、機械学習 というように
出題数が多いものから手をつけました。
後々振り返ってみても、各章ごとに出題数は大きく偏りがあったので
有効かつ限られた時間の中では効率的に学習できたと思います。
4: 一つ一つ完全に理解するのではなく・繰り返し理解する
初段、一つ一つの項目を理解しながら学習を進めていましたが
基礎知識がない状態で、一つ一つに こだわっていると、
なかなか前に進まない状況に陥りました。
途中から方針転換し
ざっくりでいいから、理解して先に進む。
繰り返し学習しながら、少しずつ肉付けしていく。
このように学習を進めてから、スムーズに前進することができました。
今分からなくて、必ず後からわかるようになるから大丈夫。の精神。
試験勉強してみて・受かってみて
結論から。
今回、G検定を受験してみて本当に良かったです。
理由は、AIまわりのドメイン用語を聞いたときに
パッと知識の結びつきができるようになったからです。
CNN? 画像認識によく使われるモデルね。
画像のように2次元情報の位置情報を活かせるモデルね。
RNN? 時系列情報を活かしたニューラルネットワークね。
過去の情報を活かすことで、翻訳や音声認識に効果があるのね。
といった具合です。
AIに関する基礎知識がインプットされたことで、
最新AIに関するニュースも理解しやすくなりました。
next step
今回、得た知識を基に以下の
チャレンジをして行こうかと思います。
- 資格・学習
- E検定
- 創作
- AI技術を使ったシステム構築